Module 1: Importing Data Sets
Data Science with Python - Key Libraries
Python libraries are collections of functions and methods that allow performing various actions without writing extensive code. They offer built-in modules for different functionalities, providing a broad range of facilities.
Categories of Python Data Analysis Libraries:
- Scientific Computing Libraries
- Data Visualization Libraries
- Algorithmic Libraries
Scientific Computing Libraries
1. Pandas
- Description: Offers data structures and tools for effective data manipulation and analysis.
- Primary Instrument: DataFrame (a two-dimensional table with column and row labels).
- Features: Fast access to structured data, easy indexing functionality.
2. NumPy
- Description: Uses arrays for inputs and outputs, can be extended to objects for matrices.
- Features: Fast array processing with minor coding changes.
3. SciPy
- Description: Includes functions for advanced math problems and data visualization.
- Features: Solves complex mathematical problems.

Data Visualization Libraries
1. Matplotlib
- Description: The most well-known library for data visualization.
- Features: Great for making highly customizable graphs and plots.
2. Seaborn
- Description: A high-level visualization library based on Matplotlib.
- Features: Easy to generate various plots like heat maps, time series, and violin plots.

Algorithmic Libraries
1. Scikit-learn
- Description: Contains tools for statistical modeling, including regression, classification, clustering, etc.
- Built on: NumPy, SciPy, and Matplotlib.
2. Statsmodels
- Description: A module for exploring data, estimating statistical models, and performing statistical tests.

Reading Data with Pandas
Data acquisition is the process of loading and reading data into a notebook from various sources. Using Python’s Pandas package, we can efficiently read and manipulate data.
Key Factors:
- Format: The way data is encoded (e.g., CSV, JSON, XLSX, HDF).
- File Path: The location of the data, either on the local computer or online.
Steps to Read Data with Pandas
1. Import Pandas
import pandas as pd2. Define File Path
Specify the location of the data file.
file_path = 'path_to_your_file.csv'3. Read CSV File
Use the read_csv method to load data into a DataFrame.
df = pd.read_csv(file_path)Special Case: No Headers in CSV
If the data file does not contain headers, set header to None.
df = pd.read_csv(file_path, header=None)4. Inspect the DataFrame
Use df.head() to view the first few rows of the DataFrame.
print(df.head())Use df.tail() to view the last few rows.
print(df.tail())5. Assign Column Names
If the column names are available separately, assign them to the DataFrame.
Verify by using df.head() again.
print(df.head())6. Export DataFrame to CSV
To save the DataFrame as a new CSV file, use the to_csv method.
df.to_csv('output_file.csv', index=False)Additional Formats
Pandas supports importing and exporting of various data formats. The syntax for reading and saving different data formats is similar to read_csv and to_csv.
Exploring and Understanding Data with Pandas
Exploring a dataset is crucial for data scientists to understand its structure, data types, and statistical distributions. Pandas provides several methods for these tasks.
Data Types in Pandas
Pandas stores data in various types:
- object: String or mixed types
- float: Numeric with decimals
- int: Numeric without decimals
- datetime: Date and time
Checking Data Types
Use dtypes to view data types of each column:
print(df.dtypes)Statistical Summary
Use describe to get statistical summary:
print(df.describe())- Count: Number of non-null values
- Mean: Average value
- std: Standard deviation
- min/max: Minimum and maximum values
- 25%/50%/75%: Quartiles
Output Example:
0 1 2 3
count 205.000000 205.000000 205.000000 205.000000
mean 13.071707 25.317073 198.313659 3.256098
std 6.153123 26.021249 90.145293 1.125947
min 5.000000 4.000000 68.000000 2.000000
25% 9.000000 8.000000 113.000000 2.000000
50% 12.000000 19.000000 151.000000 3.000000
75% 16.000000 37.000000 248.000000 4.000000
max 35.000000 148.000000 540.000000 8.000000To include all columns:
print(df.describe(include='all'))Output Example:
0 1 2 3 ... 25 26 27
count 205.000000 205.000000 205.000000 205.000000 ... 205 205 205
unique NaN NaN NaN NaN ... 25 25 25
top NaN NaN NaN NaN ... value value value
freq NaN NaN NaN NaN ... 10 10 10
mean 13.071707 25.317073 198.313659 3.256098 ... NaN NaN NaN
std 6.153123 26.021249 90.145293 1.125947 ... NaN NaN NaN
min 5.000000 4.000000 68.000000 2.000000 ... NaN NaN NaN
25% 9.000000 8.000000 113.000000 2.000000 ... NaN NaN NaN
50% 12.000000 19.000000 151.000000 3.000000 ... NaN NaN NaN
75% 16.000000 37.000000 248.000000 4.000000 ... NaN NaN NaN
max 35.000000 148.000000 540.000000 8.000000 ... NaN NaN NaNFor object columns, it shows additional statistics like the number of unique values, the most frequent value (top), and its frequency (freq).
DataFrame Info
Use info for a concise summary:
df.info()- Shows index, data types, non-null counts, and memory usage.
Output Example:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 205 entries, 0 to 204
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 205 non-null int64
1 1 205 non-null int64
2 2 205 non-null int64
3 3 205 non-null int64
4 4 205 non-null object
5 5 205 non-null object
6 6 205 non-null object
7 7 205 non-null object
8 8 205 non-null object
9 9 205 non-null object
10 10 205 non-null object
dtypes: int64(4), object(24)
memory usage: 45.0+ KBAccessing Databases with Python: SQL APIs and Python DB APIs
Databases are essential tools for data scientists, and Python provides powerful libraries for connecting to and interacting with databases. This module covers the basics of using Python to access databases through SQL APIs and Python DB APIs.
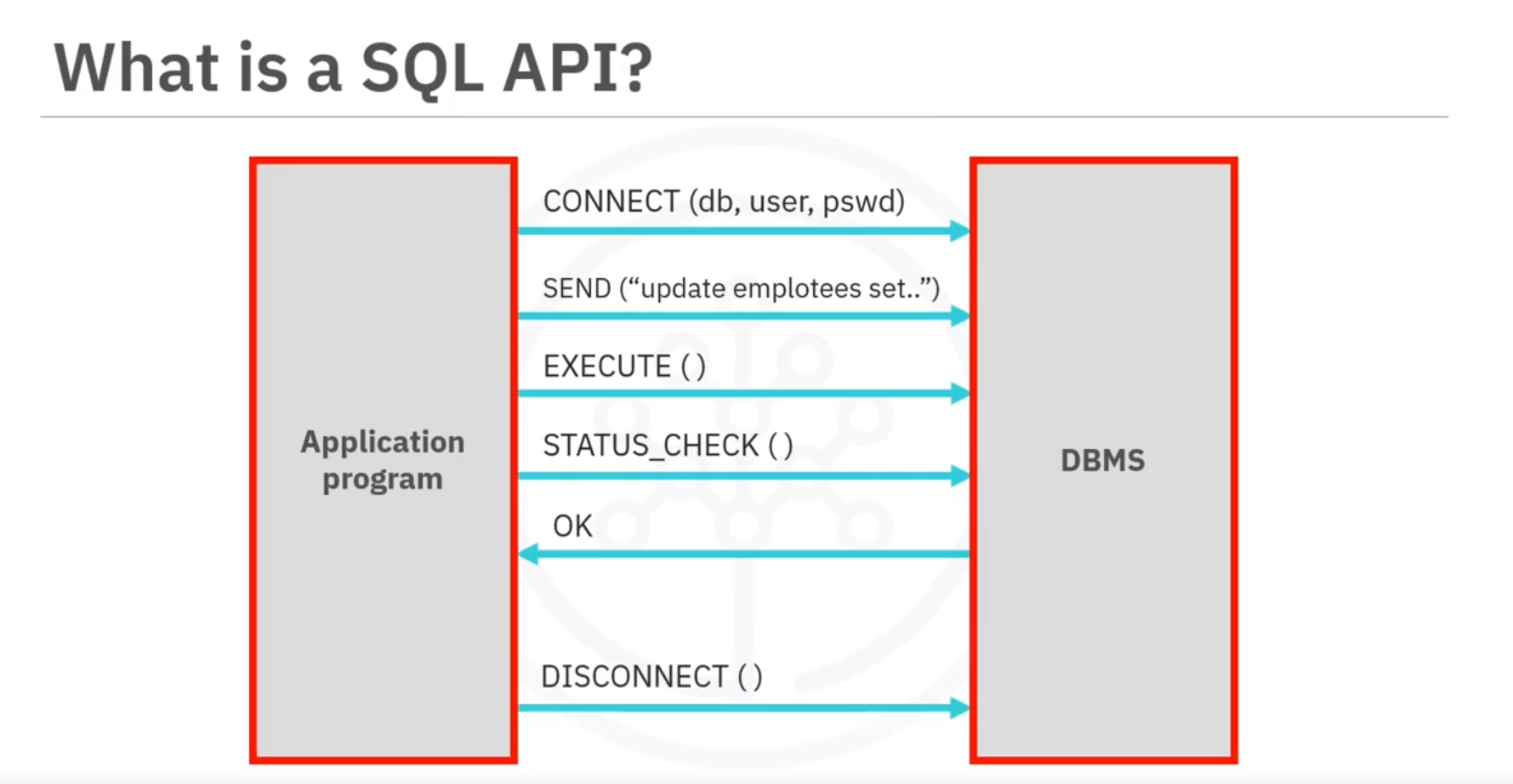
SQL APIs
- Definition: SQL API consists of library function calls that act as an interface for the Database Management System (DBMS).
- Functionality: Allows Python programs to send SQL statements, retrieve query results, and manage database connections and transactions.
Basic Operations of SQL API
- Connecting to Database:
- Use API calls to establish a connection between the Python program and the DBMS.
- Executing SQL Statements:
- Build SQL statements as text strings and pass them to the DBMS using API calls.
- Handling Errors and Status:
- Use API calls to check the status of DBMS requests and handle errors during database operations.
- Disconnecting from Database:
- End database access with an API call that disconnects the Python program from the database.
Python DB API
- Definition: Python DB API is the standard API for accessing relational databases in Python.
- Advantages: Enables writing a single program that works across multiple types of relational databases.
Key Concepts in Python DB API
- Connection Objects:
- Used to connect to a database and manage transactions.
- Created using the
connectfunction from the database module.
- Cursor Objects:
- Used to execute queries and fetch results from the database.
- Similar to a cursor in text processing, used to navigate through query results.
Methods with Connection Objects
cursor()Method:- Returns a new cursor object using the connection.
commit()Method:- Commits any pending transaction to the database.
rollback()Method:- Causes the database to roll back to the start of any pending transaction.
close()Method:- Closes the database connection to free up resources.
Methods with Cursor Objects
execute()Method:- Executes a SQL query using the cursor.
- Used for running INSERT, UPDATE, DELETE, and SELECT queries.
Python Application Example
- Import Database Module:
- Import the database module and use the
connectfunction to establish a connection.
- Import the database module and use the
- Connect to Database:
- Use
connectwith database name, username, and password parameters to get a connection object.
- Use
- Create Cursor:
- Create a cursor object on the connection to execute queries and fetch results.
- Execute Queries:
- Use
execute()function of the cursor to run queries andfetchall()to fetch query results.
- Use
- Close Connection:
- Use the
close()method on the connection object to release resources after queries are complete.
- Use the

Conclusion
Understanding SQL APIs and Python DB APIs allows data scientists to effectively manage and analyze data stored in relational databases using Python. Always remember to manage connections properly to optimize resource usage.
Cheat Sheet: Data Wrangling
Read the CSV
Read the CSV file containing a data set to a pandas data frame
df = pd.read_csv(<CSV_path>, header=None) # load without header
df = pd.read_csv(<CSV_path>, header=0) # load using first row as header
Print first few entries
Print the first few entries (default 5) of the pandas data frame
df.head(n) # n=number of entries; default 5Print last few entries
Print the last few entries (default 5) of the pandas data frame
df.tail(n) # n=number of entries; default 5Assign header names
Assign appropriate header names to the data frame
df.columns = headersReplace "?" with NaN
Replace the entries "?" with NaN entry from Numpy library
df = df.replace("?", np.nan)Retrieve data types
Retrieve the data types of the data frame columns
df.dtypesRetrieve statistical description
Retrieve the statistical description of the data set. Defaults use is for only numerical data types. Use include="all" to create summary for all variables.
df.describe() # default use df.describe(include="all")Retrieve data set summary
Retrieve the summary of the data set being used, from the data frame
df.info()Save data frame to CSV
Save the processed data frame to a CSV file with a specified path
df.to_csv(<output CSV path>)