
Module 3: Keras and Deep Learning Libraries
Deep Learning Libraries and Frameworks
Overview
Deep learning frameworks offer various functionalities for building, training, and deploying machine learning models. Below are some of the most popular libraries and their key features.
Popular Deep Learning Libraries
- TensorFlow
- PyTorch
- Keras
- Theano
1. TensorFlow
Description
TensorFlow is the most widely used deep learning library, developed by Google and released in 2015. It is mainly used in production and large-scale projects. TensorFlow supports a vast range of tools for deep learning and has an active community contributing to its continuous development.
Features
- High scalability for production
- Support for deployment on multiple platforms
- Large, active community
Additional Note: GitHub link for TensorFlow - https://github.com/tensorflow/tensorflow

2. PyTorch
Description
PyTorch, developed by Facebook in 2016, has gained popularity in academic and research settings. It emphasizes flexibility and dynamic computation graphs, making it ideal for applications requiring custom deep learning models. PyTorch is a cousin of the Lua-Based Torch Framework, and is a strong competitor
Features
- Dynamic computational graph
- Strong academic presence
- Easier debugging and optimization

3. Keras
Description
Keras is a high-level API for building neural networks. It runs on top of TensorFlow and simplifies model building with a user-friendly interface, making it a great option for beginners and rapid prototyping.
Features
- Simplified syntax for rapid development
- Can run on top of TensorFlow or Theano
- User-friendly and easy to learn

Comparison of Libraries
- TensorFlow: Best for large-scale production environments.
- PyTorch: Ideal for research and academic settings.
- Keras: Preferred for beginners and fast prototyping.
Summary
Deep learning libraries provide the foundation for building and optimizing neural networks. TensorFlow, PyTorch, and Keras are widely used, each suited for different applications depending on production needs, flexibility, and ease of use.
- TensorFlow: Developed by Google, TensorFlow is a deep learning library in Python. It is widely used in both research and production. TensorFlow supports static computational graphs and offers flexibility for large-scale machine learning tasks.
- PyTorch: Developed by Facebook, PyTorch is a deep learning library in Python known for its dynamic computational graph and ease of use, particularly in research and experimentation. PyTorch has gained significant popularity in academic settings and is often preferred for building custom deep learning models.
- Keras: Keras is a high-level deep learning library written in Python. It acts as an API that runs on top of lower-level libraries like TensorFlow. Keras is known for its simplicity and ease of use, making it a great choice for beginners in deep learning.
- Theano: Theano is a deep learning library built in Python. It was one of the first libraries in this field, developed by the Montreal Institute for Learning Algorithms. While it was powerful for earlier deep learning development, it is now largely deprecated and no longer actively maintained.
Building Regression Models with Keras
Overview of Keras Library
The Keras library is a high-level API for building and training deep learning models. It simplifies the process of developing neural networks and can run on top of other deep learning libraries like TensorFlow.
Importing and Using Keras
- Importing Keras:
- Import the Keras library and check the backend:
import keras print("Keras Backend:", keras.backend.backend())
- The output will display the backend used, typically TensorFlow.
- Import the Keras library and check the backend:
- Preparing the Data:
- Example data consists of the compressive strength of concrete samples based on their ingredients. The data is organized in a pandas DataFrame named
concrete_data.
- Split the DataFrame into predictors and target variables:
predictors = concrete_data[['cement', 'slag', 'flyash', 'water', 'superplasticizer', 'coarseaggregate', 'fineaggregate']] target = concrete_data['strength']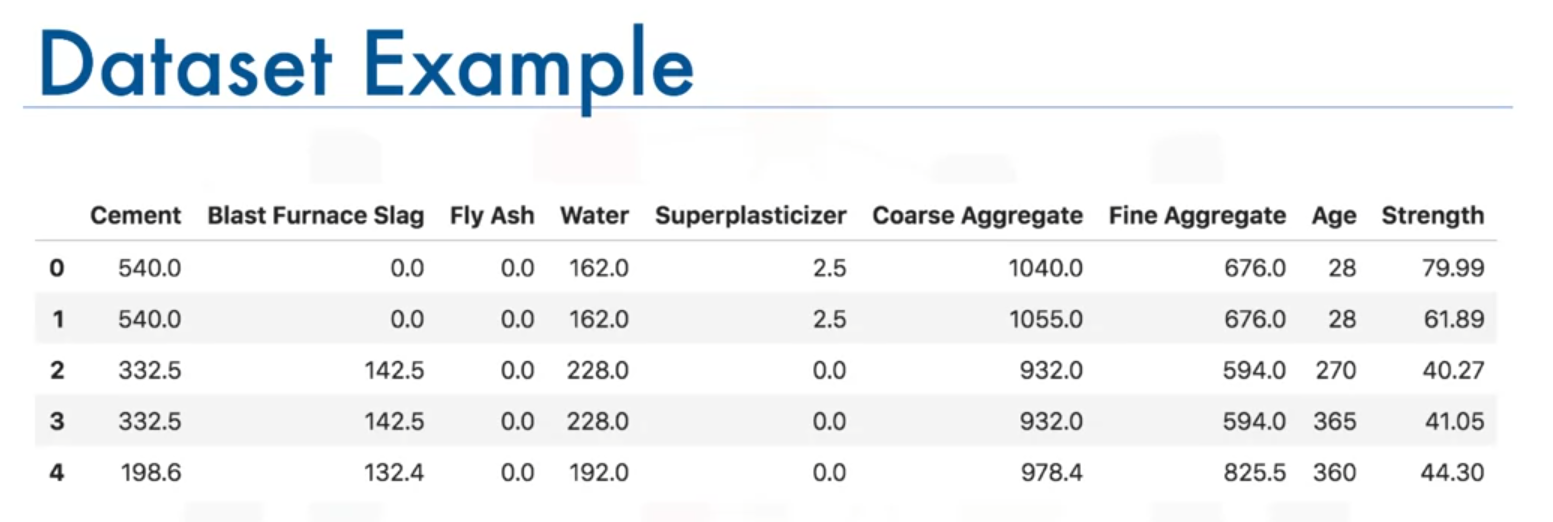
- Example data consists of the compressive strength of concrete samples based on their ingredients. The data is organized in a pandas DataFrame named
Building a Regression Model
- Creating the Model:
- Import necessary modules:
from keras.models import Sequential from keras.layers import Dense
- Classes:
SequentialModel: A linear stack of layers where you add layers sequentially.
DenseLayer: A fully connected layer in the network where each neuron in the layer is connected to every neuron in the previous layer.
- Initialize the Sequential model:
model = Sequential()
- Import necessary modules:
- Adding Layers:
- Add hidden and output layers:
model.add(Dense(5, input_shape=(8,), activation='relu')) model.add(Dense(5, activation='relu')) model.add(Dense(1))
- Parameters Explained:
Dense(units, input_shape=None, activation=None):units: Number of neurons in the layer.
input_shape: Shape of input data (only needed for the first layer). For example,input_shape=(8,)indicates 8 features.
activation: Activation function used by the layer. 'relu' is used for hidden layers, and no activation function is specified for the output layer to allow continuous output.
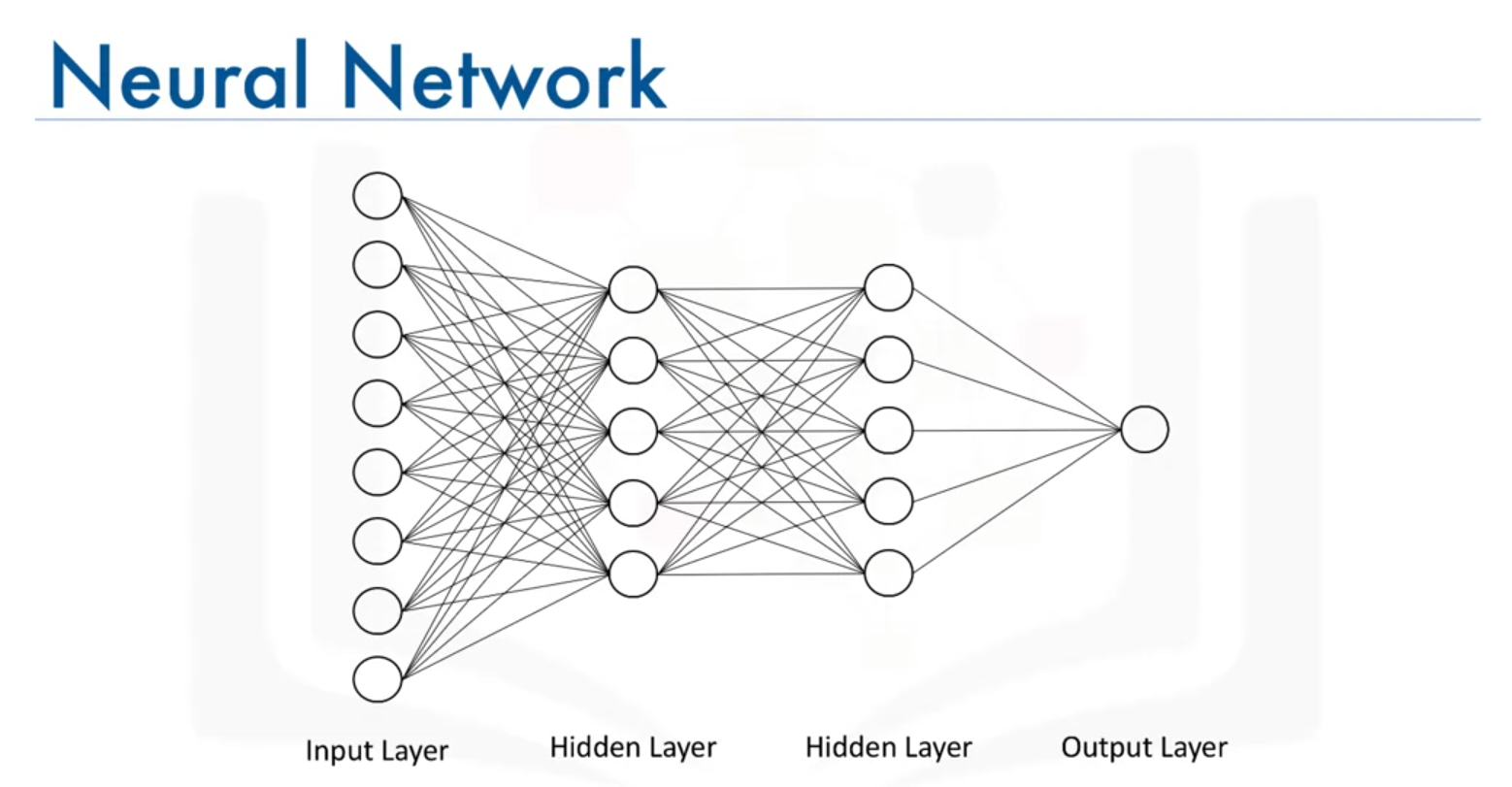
- Add hidden and output layers:
- Compiling the Model:
- Define the optimizer and loss function:
model.compile(optimizer='adam', loss='mean_squared_error')
- Parameters Explained:
optimizer: Optimization algorithm used for training. 'adam' is an adaptive optimizer that adjusts the learning rate during training (itself).
loss: Loss function used to measure the difference between predicted and actual values. 'mean_squared_error' is used for regression tasks.
- Define the optimizer and loss function:
- Training the Model:
- Fit the model to the data:
model.fit(predictors, target, epochs=100)
- Parameters Explained:
predictors: Input data (features).
target: Output data (labels).
epochs: Number of iterations over the entire training data.
- Fit the model to the data:
- Making Predictions:
- Use the model to predict new data:
predictions = model.predict(new_data)
- Parameters Explained:
new_data: New input data for which predictions are to be made.
predictions: The output from the model for the new data.
- Use the model to predict new data:

Conclusion
Keras simplifies the process of building and training neural networks. For regression tasks, a basic model can be built with just a few lines of code, making it accessible and efficient for rapid development. For more detailed information, refer to the Keras documentation on optimizers, models, and methods.
Additional Notes:
Keras Activation Functions: https://keras.io/activations/
Keras Models:
https://keras.io/models/about-keras-models/#about-keras-models
Keras Optimizers:
https://keras.io/optimizers/
Keras Metrics:
https://keras.io/metrics/
Building Classification Models with Keras
Overview of Classification with Keras
The Keras library is a high-level API for building and training deep learning models. In this example, Keras is used to build a classification model that predicts whether purchasing a car is a good choice based on the car's attributes.
Setting Up Keras
- Importing Necessary Libraries:
- Import the Keras library, the Sequential model, and the Dense layer:
from keras.models import Sequential from keras.layers import Dense from keras.utils import to_categorical
- Preparing the Data:
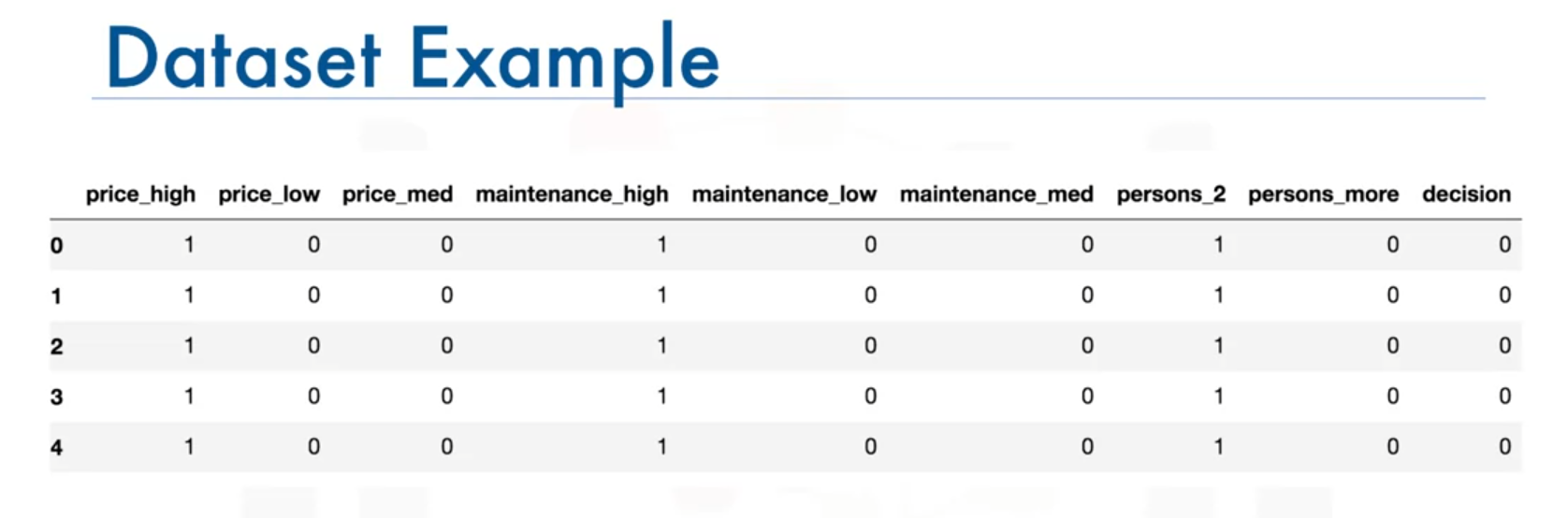
- Example dataset:
car_data, cleaned and one-hot encoded. The dataset includes features such as price, maintenance cost, and capacity.
- Split the dataset into predictors and target variables:
predictors = car_data[['price_high', 'price_medium', 'price_low', 'maint_high', 'maint_medium', 'maint_low', 'capacity_two', 'capacity_more']] target = car_data['decision']- Transforming the Target Variable:
- Convert the target variable into one-hot encoded format using
to_categorical:
- Convert the target variable into one-hot encoded format using
target = to_categorical(target) - Example dataset:
Building a Classification Model
- Creating the Model:
- Initialize the Sequential model:
model = Sequential()
- Adding Layers:
- Add hidden and output layers:
model.add(Dense(5, input_shape=(8,), activation='relu')) model.add(Dense(5, activation='relu')) model.add(Dense(4, activation='softmax'))Parameters Explained:
Dense(units, input_shape=None, activation=None):- units: Number of neurons in the layer.
- input_shape: Shape of input data (only needed for the first layer). For example,
input_shape=(8,)indicates 8 features.
- activation: Activation function used by the layer. 'relu' is used for hidden layers, and 'softmax' is used for the output layer to provide probabilities for each class.
- Compiling the Model:
- Define the optimizer and loss function:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])Parameters Explained:
optimizer: Optimization algorithm used for training. 'adam' is an adaptive optimizer that adjusts the learning rate during training.
loss: Loss function used to measure the difference between predicted and actual values. 'categorical_crossentropy' is used for multi-class classification tasks.
metrics: Evaluation metric used to measure model performance. 'accuracy' is a built-in metric in Keras.
- Training the Model:
- Fit the model to the data:
model.fit(predictors, target, epochs=100)Parameters Explained:
predictors: Input data (features).
target: Output data (labels).
epochs: Number of iterations over the entire training data.
- Making Predictions:
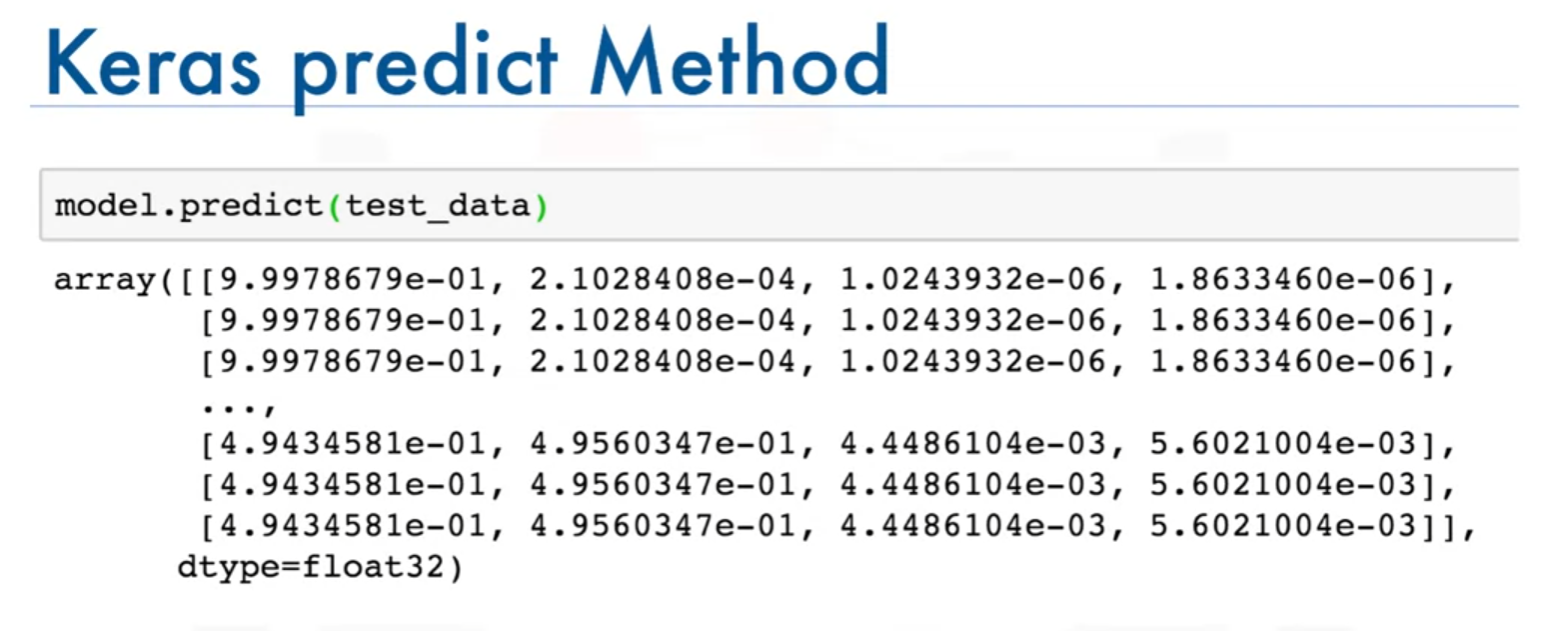
- Use the model to predict new data:
predictions = model.predict(new_data)Parameters Explained:
new_data: New input data for which predictions are to be made.
predictions: The output from the model for the new data. Each prediction will be a probability distribution over the classes.

Conclusion
Keras provides a straightforward approach to building and training classification models. For classification tasks, the model architecture and training process are similar to those used for regression, with the key differences being the activation functions and loss functions used. For more detailed information, refer to the Keras documentation on optimizers, models, and methods.