
Module 1: Introduction to Machine Learning
What is Machine Learning?
Machine Learning is a subfield of computer science that gives computers the ability to learn from data without being explicitly programmed. It involves the development of algorithms that can recognize patterns, make decisions, and improve themselves over time.
How Does Machine Learning Work?
Machine Learning algorithms, inspired by the human learning process, iteratively learn from data. These algorithms allow computers to discover hidden insights and patterns within large datasets. The models created through Machine Learning can assist in a variety of tasks, such as object recognition, text summarization, recommendation systems, and more.
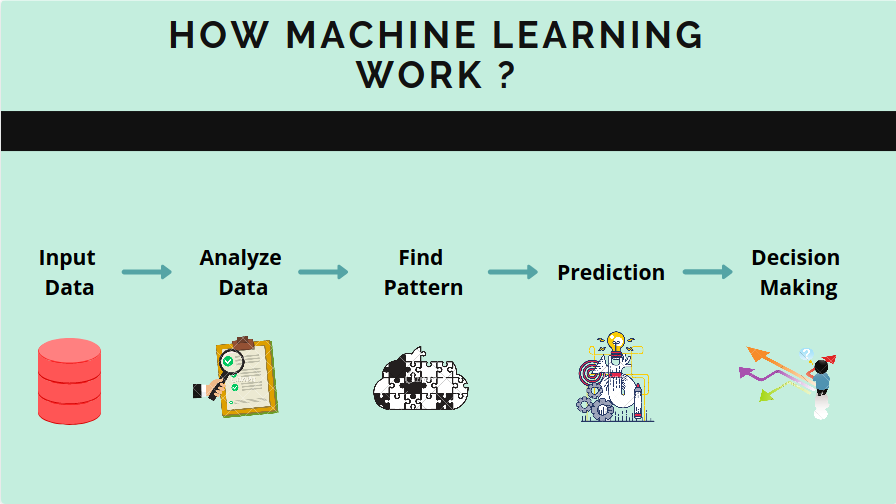
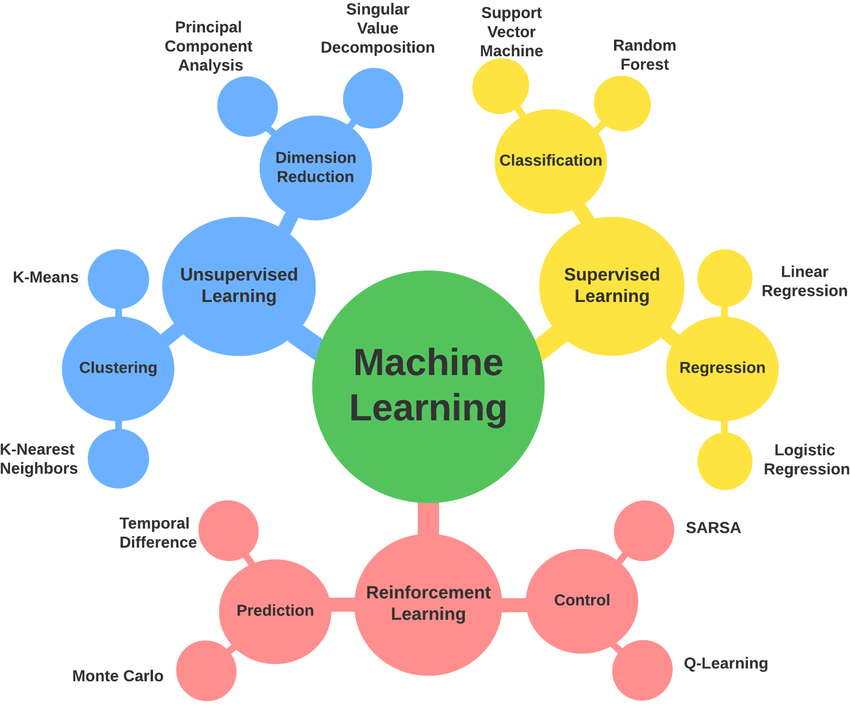
Major Machine Learning Techniques
Regression
- Definition: A method used to predict continuous values (e.g., prices, temperatures) based on input features.
- Scenario: House Price Prediction
- Description: A real estate company wants to predict house prices based on features like size, number of bedrooms, and location. They use a linear regression model.
- Data:
- Size (square feet)
- Number of bedrooms
- Location (neighborhood)
- Age of the house
- Historical sale prices
- Outcome: The model predicts the price of a house given its features.
- Benefit: Helps the company set competitive prices and assists buyers in making informed decisions.
Classification
- Definition: A method used to predict categories or labels (e.g., spam or not spam) based on input features.
- Scenario: Email Spam Detection
- Description: An email service provider wants to filter out spam emails. They use a logistic regression or decision tree classifier.
- Data:
- Email content (text)
- Metadata (sender address, frequency of keywords)
- Label (spam or not spam)
- Outcome: The model classifies emails as either spam or not spam.
- Benefit: Reduces the number of spam emails reaching users' inboxes, improving user experience.
Clustering
- Definition: A method used to group similar data points together without predefined categories.
- Scenario: Customer Segmentation
- Description: An e-commerce company segments its customers based on purchasing behavior using the K-means clustering algorithm.
- Data:
- Customer Age
- Annual Income
- Spending Score
- Outcome: Customers are grouped into clusters with similar behaviors.
- Benefit: Allows for targeted marketing strategies.
Association Rule Learning
- Definition: A method used to find relationships between items in large datasets.
- Scenario: Market Basket Analysis
- Description: A grocery store identifies items frequently bought together using the Apriori algorithm.
- Data:
- Transaction ID
- List of items purchased
- Outcome: Rules like {Bread, Butter} → {Milk} are discovered.
- Benefit: Optimizes product placement and promotions.
Anomaly Detection
- Definition: A method used to identify unusual patterns that do not conform to expected behavior.
- Scenario: Fraud Detection
- Description: A bank wants to detect fraudulent transactions. They use anomaly detection techniques.
- Data:
- Transaction amount
- Transaction location
- Time of transaction
- Historical transaction data
- Outcome: The model flags suspicious transactions.
- Benefit: Helps prevent fraud and protects customers.
Sequence Mining
- Definition: A method used to discover patterns in sequential data.
- Scenario: Customer Purchase Patterns
- Description: An online retailer wants to find patterns in the sequence of items customers purchase. They use sequence mining techniques.
- Data:
- Transaction sequences
- Items purchased in order
- Outcome: Patterns like customers often buying a phone case after purchasing a phone are discovered.
- Benefit: Helps in creating better marketing strategies.
Dimensionality Reduction
- Definition: A method used to reduce the number of input variables in a dataset.
- Scenario: Data Visualization
- Description: A data scientist wants to visualize high-dimensional data. They use Principal Component Analysis (PCA).
- Data:
- Multidimensional data points
- Outcome: The data is reduced to two or three principal components for visualization.
- Benefit: Helps in understanding data structure and identifying patterns.
Recommendation Systems
- Definition: A method used to suggest items to users based on various factors.
- Scenario: Movie Recommendations
- Description: A streaming service wants to recommend movies to its users. They use a recommendation system.
- Data:
- User viewing history
- Movie ratings
- Genre preferences
- Outcome: The system suggests movies that users are likely to enjoy.
- Benefit: Enhances user experience and increases engagement.
Note
Sequence mining identifies patterns based on the order of events, while association rule learning focuses on identifying co-occurrence patterns without considering the order of items.
Understanding Artificial Intelligence, Machine Learning, and Deep Learning
Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are often used interchangeably but refer to distinct concepts in the realm of computer science:
- Artificial Intelligence (AI) encompasses the broad goal of simulating human intelligence in machines. It includes fields like computer vision, natural language processing, creativity, and summarization.
- Machine Learning (ML) is a subset of AI that focuses on algorithms and statistical models that enable computers to perform tasks without explicit programming. ML involves learning from data and examples to improve performance on specific tasks.
- Deep Learning (DL) represents a specialized area within ML that involves algorithms inspired by the structure and function of the human brain's neural networks. DL enables computers to learn from large amounts of data and make decisions autonomously.
In summary:
- AI aims to make machines intelligent across various domains.
- ML provides the statistical tools for machines to learn from data and improve over time.
- DL utilizes deep neural networks to achieve high levels of automation and performance in tasks like image and speech recognition.
Introduction to Python for Machine Learning
Python is a popular and powerful general-purpose programming language that has emerged as the preferred language among data scientists. Writing machine learning algorithms using Python is highly effective, especially with numerous pre-implemented modules and libraries available.
Key Python Packages for Machine Learning
- NumPy: A math library for working with N-dimensional arrays. It enables efficient computation and is superior for tasks involving arrays, dictionaries, functions, datatypes, and image processing.
- SciPy: A collection of numerical algorithms and domain-specific toolboxes, including signal processing, optimization, and statistics. Ideal for scientific and high-performance computation.
- Matplotlib: A popular plotting package providing both 2D and 3D plotting capabilities. Essential for visualizing data in real-world problem-solving.
- Pandas: A high-level library offering high-performance, easy-to-use data structures and functions for data importing, manipulation, and analysis, particularly for numerical tables and time series.
- SciKit Learn: A comprehensive library of machine learning algorithms and tools. It integrates well with NumPy and SciPy and simplifies the implementation of machine learning models.
SciKit Learn
SciKit Learn is a comprehensive machine learning library that integrates seamlessly with NumPy and SciPy. It simplifies the implementation of machine learning models through several streamlined steps:
- Pre-processing: Standardizing datasets to handle outliers and varying scales, transforming raw feature vectors into suitable forms for modeling.
- Train-Test Split: Dividing datasets into training and testing subsets to validate model performance.
- Building and Training Models: Initializing and configuring algorithms, such as support vector classification, and fitting them to training data.
- Making Predictions: Using the test data to evaluate the model’s performance.
- Evaluation: Assessing accuracy with metrics like a confusion matrix, visualizing model performance.
- Model Exporting: Saving trained models for future use, enabling easy deployment.
A typical workflow with SciKit Learn involves pre-processing the data, splitting it into training and testing sets, building and training a classifier, making predictions, evaluating the model, and saving it for future use.
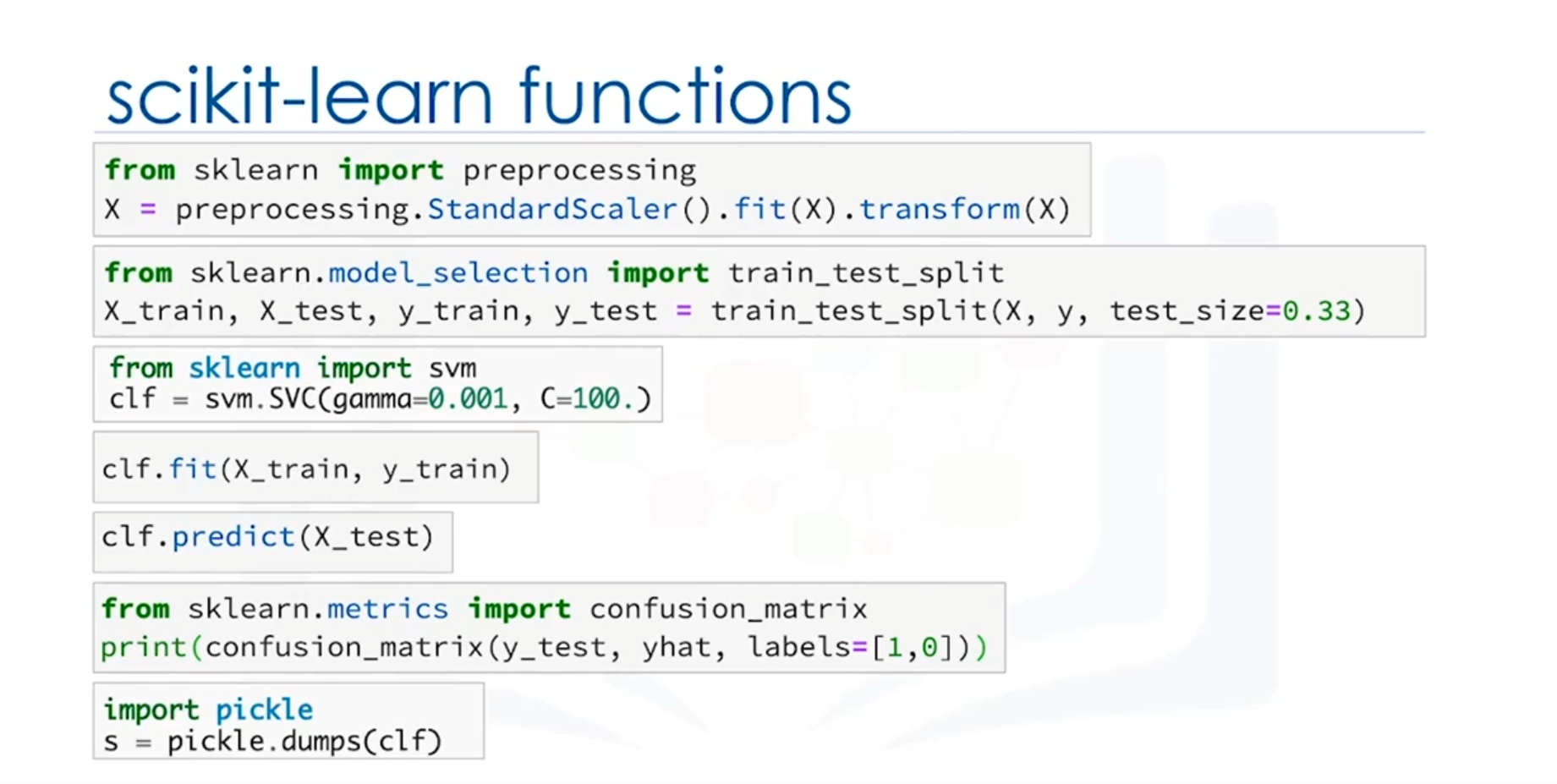
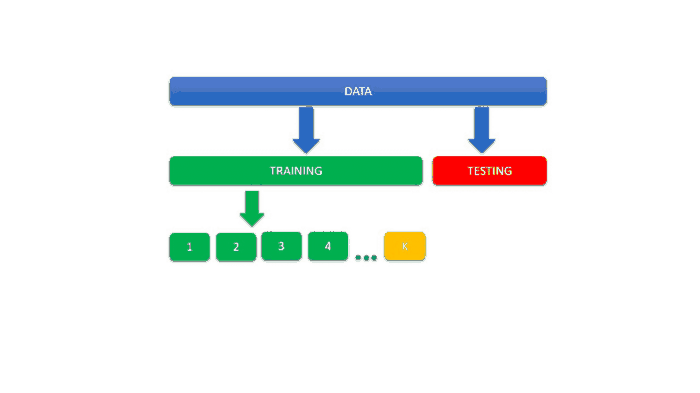
Understanding and leveraging these packages, especially SciKit Learn, simplifies the machine learning process and reduces the amount of coding required compared to using pure Python or other individual packages.
Supervised vs Unsupervised Algorithms
Understanding the difference between supervised and unsupervised learning is fundamental in machine learning.
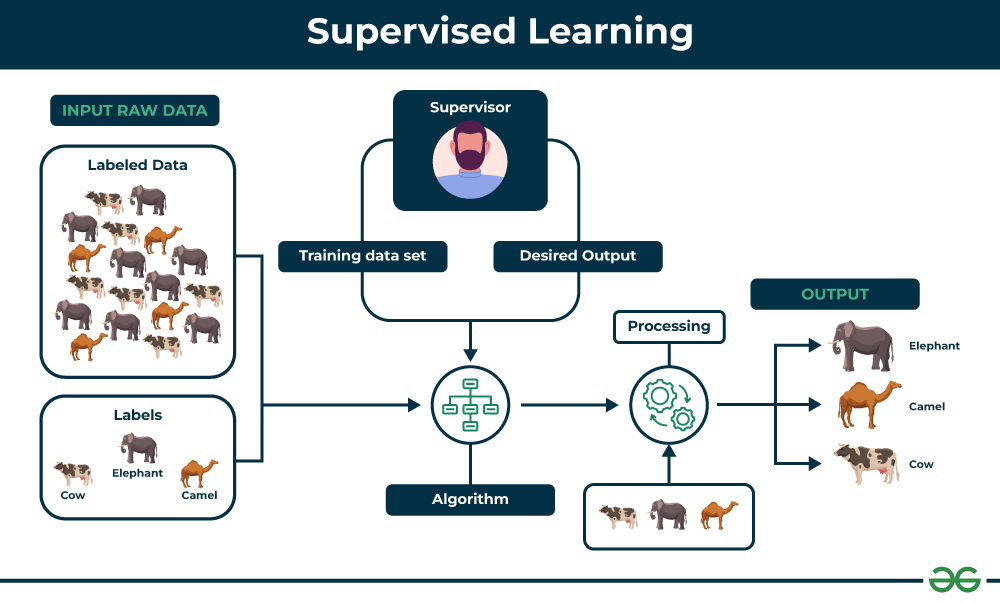
Supervised Learning
Supervised learning involves teaching a machine learning model using a labeled dataset. This means the model is trained on data where the input features and the output labels are known. For example, in a cancer dataset, features like clump thickness and cell size (attributes) are used to predict if a cell is malignant or benign (label). The goal is to predict future instances based on this training.
- Types of Supervised Learning:
- Classification: Predicts discrete class labels. For example, classifying emails as spam or not spam.
- Regression: Predicts continuous values. For example, predicting the CO2 emission of a car based on its engine size and number of cylinders.
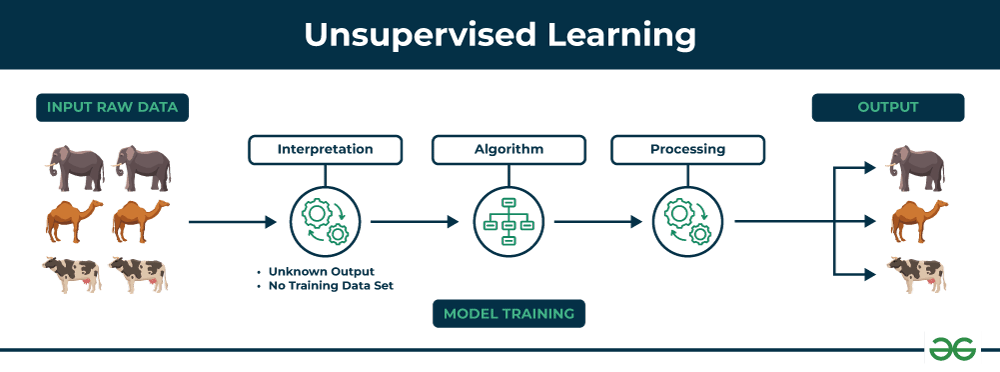
Unsupervised Learning
Unsupervised learning involves training a model on data without labeled responses. The model tries to learn the underlying structure of the data on its own.
- Common Unsupervised Learning Techniques:
- Clustering: Grouping data points into clusters based on their similarity. It is widely used for customer segmentation, organizing music genres, etc.
- Dimensionality Reduction: Reducing the number of features in the data to simplify the model and make the classification easier.
- Market Basket Analysis: Identifying items that frequently co-occur in transactions.
- Density Estimation: Exploring the data to find some underlying structure.
Key Differences Between Supervised and Unsupervised
- Data:
- Supervised Learning: Uses labeled data.
- Unsupervised Learning: Uses unlabeled data.
- Techniques:
- Supervised Learning: Includes classification and regression.
- Unsupervised Learning: Includes clustering, dimensionality reduction, market basket analysis, and density estimation.
- Outcome Control:
- Supervised Learning: More controllable environment due to labeled data.
- Unsupervised Learning: Less controllable, model draws conclusions from the data without predefined labels.
Recap
The main distinction between supervised and unsupervised learning is that supervised learning uses labeled data to train models, while unsupervised learning uses unlabeled data, allowing the model to find hidden patterns or intrinsic structures. Supervised learning methods are more straightforward in terms of evaluation and control compared to the often complex algorithms and less predictable outcomes in unsupervised learning.